
Business case •
Blog •
Article •
Blog •
Article •
easyKost & random forests

Statistical Learning & Random Forests History
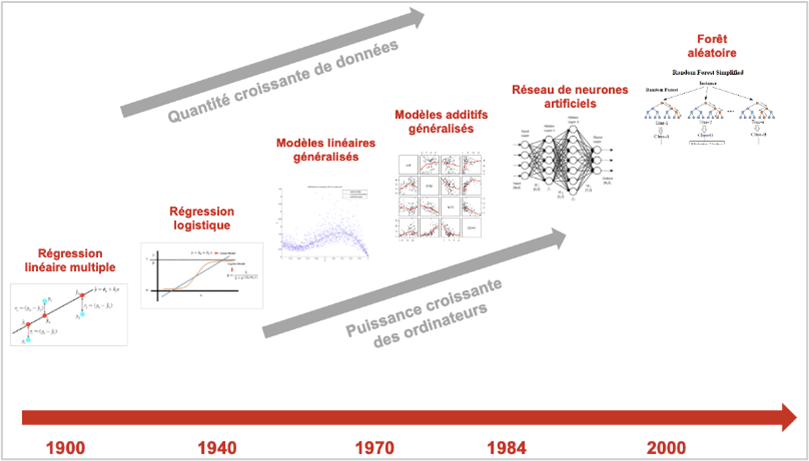
Over the years, statistics has had a lot of progress, both in terms of algorithms and mathematical models, going from multiple linear regressions in the 1900s, to generalized additive models in the 1970s, to arrive now to the deployment of AI (Artificial Intelligence) in the mathematical model of random forests, which easyKost uses.
Random forest is a very powerful statistical method, used to solve classification and regression problems.
A random forest-based algorithm performs machine learning on multiple decision trees* which, when combined, yield a highly accurate final estimate.
During the construction of the forest, some individuals are used to learn and others serve as tests, which makes it possible to validate the learning and to have an indicator of the quality of the method.
The random forest model makes it possible to obtain more precise encryption results and to have complex and efficient data analysis capacities, compared to the results obtained using the other models.
* A decision tree is a predictive statistical model that makes it possible to evaluate the value of a characteristic of a system from the observation of other characteristics of the same system. The leaves represent the different values of the target variable sought and the branches the different combinations of input variables that make it possible to obtain these values. The relevance of a decision tree is based on the choice of the root variable that conditions the deployment of the branches and on the best attributes to place on each branch.
Artificial intelligence in easyKost
The AI algorithms, used by easyKost, based on statistical methods (random forests and Bayesian approaches), are recognized by the international statistical community.
These algorithms allow:
- To estimate the cost of a new product and/or service based on the selected cost-drivers.
- To calculate an interval on the estimated cost.
- Order the cost-drivers and thus determine the most impactful.
- Perform Reverse Costing calculations on a target value.
- To define a level of confidence in the estimate of a cost.
easyKost uses random forests in the following way:
Based on initial reference quotes, {n} new databases are created by performing draws with discounts from the initial database. This is the Bootstrap statistical technique, whose objective is to imitate the process that generated the data, and therefore to have access to {n} databases of the same type.
Each database will give rise to a decision tree which will constitute the forest and will allow, by aggregating the predictions of each tree, to give the final prediction.
So, when estimating a cost, the characteristics of the new product/service will go through each tree to give a result that will be averaged. This is the statistical principle of “Bagging”: the average reduces the variance. This method allows you to have extreme confidence in the final result, knowing that on average a random forest in easyKost is made up of at least 500 trees. This confidence in the predictions is reinforced using independent trees.
For this, the creation of new databases is not carried out with all the variables, but with a random selection of a subset of variables. The importance of the variables being given by the number of times the variable has been used in the trees.
Thus, this method makes it possible to take into account all kinds of links between variables and especially interactions: the impact of a variable on the cost is not the same according to the methods or the values of another variable.
Also discover
All articles


Business case •
Article •